Anthropic Claude LLM Models
Anthropic’s Claude models are built with a strong focus on reliability, safety, and advanced reasoning. From lightning-fast lightweight models to frontier-level intelligence, Claude powers real-world use cases with options for instant responses or extended, step-by-step thinking.

Ce Qui Se Démarque - Anthropic Claude LLM Models

Hybrid Reasoning
Switch between instant outputs and Extended Thinking for deeper step-by-step reasoning.

Frontier Performance
Opus delivers state-of-the-art results across reasoning, coding, and analysis.

Safety by Design
Built with Anthropic’s Constitutional AI to reduce harmful or biased outputs.

Enterprise Reliability
Consistent performance with versions optimized for latency, throughput, and scale.

Code & Agent Strengths
Strong on software engineering, debugging, and agentic workflows.

Long-Context Capabilities
Supports extended context windows for large documents and multi-step tasks.
Ce Que Vous Pouvez Faire - Anthropic Claude LLM Models
Analyze documents, images, and data in multiple languages including Spanish, Japanese, and French.
Code complete software projects from planning to bug fixes and major refactors.
Reason through graduate-level problems in math, science, and logic.
Create and edit spreadsheets, documents, presentations, and PDFs directly.
Process massive amounts of text and images in a single conversation.
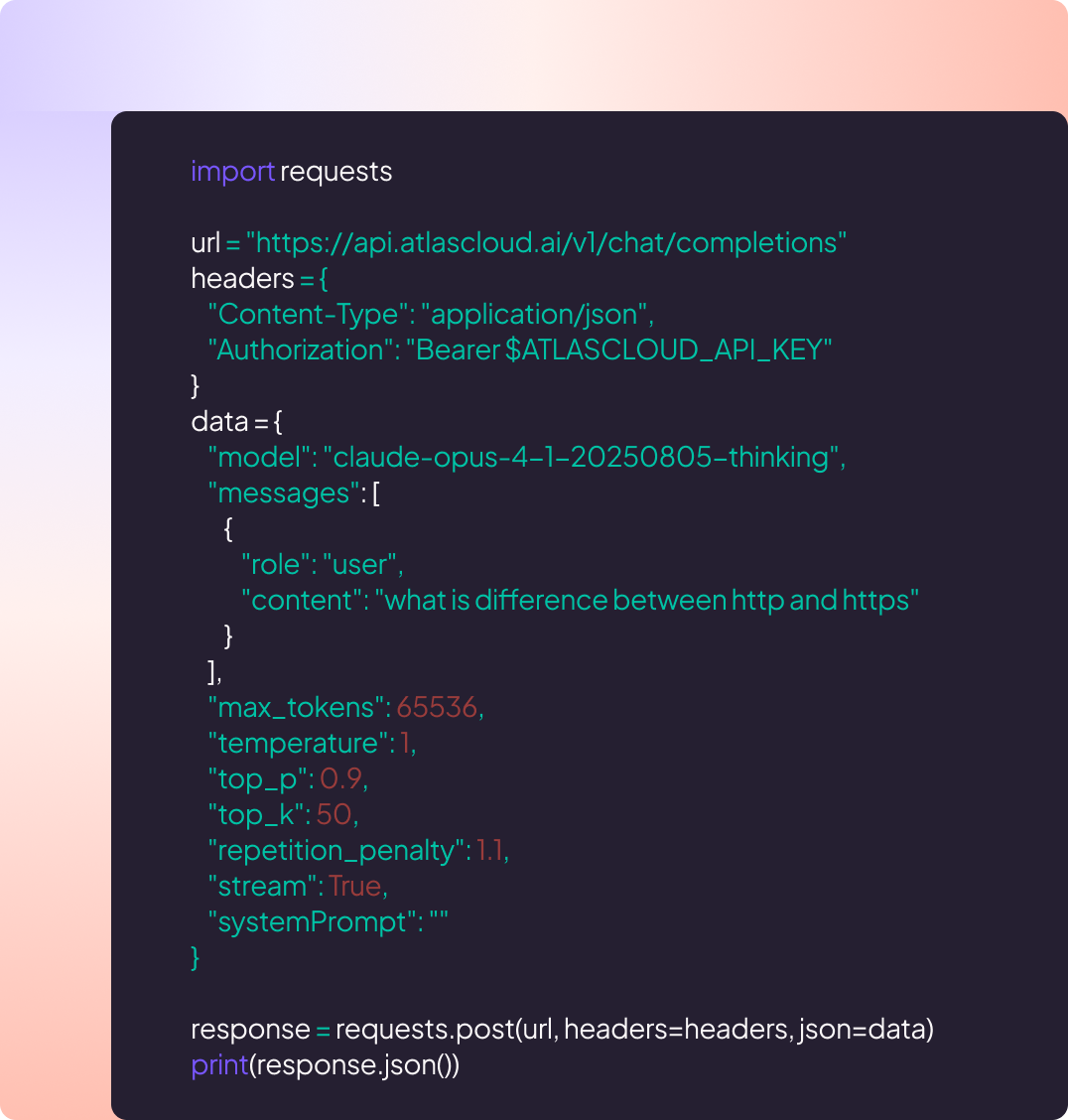
Pourquoi Utiliser Anthropic Claude LLM Models sur Atlas Cloud
Combiner les modèles Anthropic Claude LLM Models avancés avec la plateforme accélérée par GPU d'Atlas Cloud offre des performances, une évolutivité et une expérience développeur inégalées.
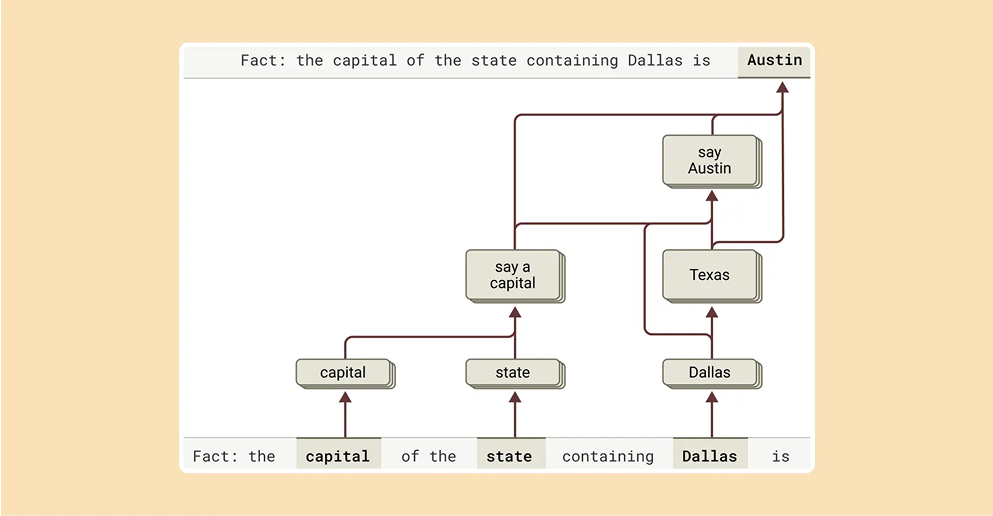
Here's how research-driven Claude performs multi-step reasoning: first extracting that Dallas is located in Texas, then identifying Austin as the state capital.
Performance et Flexibilité
Faible Latence :
Inférence optimisée par GPU pour un raisonnement en temps réel.
API Unifiée :
Exécutez Anthropic Claude LLM Models, GPT, Gemini et DeepSeek avec une seule intégration.
Tarification Transparente :
Facturation prévisible par token avec options serverless.
Entreprise et Échelle
Expérience Développeur :
SDK, analytiques, outils de fine-tuning et modèles.
Fiabilité :
99,99% de disponibilité, RBAC et journalisation conforme.
Sécurité et Conformité :
SOC 2 Type II, alignement HIPAA, souveraineté des données aux États-Unis.
Explorer Plus de Familles
Z.ai LLM Models
The Z.ai LLM family pairs strong language understanding and reasoning with efficient inference to keep costs low, offering flexible deployment and tooling that make it easy to customize and scale advanced AI across real-world products.
Seedance 1.5 Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Its AI analyzes motion, setting, and timing to generate matching ambient sounds, then adds creative depth through spatial audio and atmosphere, making each video feel natural, immersive, and story-driven.
Moonshot LLM Models
The Moonshot LLM family delivers cutting-edge performance on real-world tasks, combining strong reasoning with ultra-long context to power complex assistants, coding, and analytical workflows, making advanced AI easier to deploy in production products and services.
Wan2.6 Video Models
Wan 2.6 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. Wan 2.6 will let you create videos of up to 15 seconds, ensuring narrative flow and visual integrity. It is perfect for creating YouTube Shorts, Instagram Reels, Facebook clips, and TikTok videos.
Flux.2 Image Models
The Flux.2 Series is a comprehensive family of AI image generation models. Across the lineup, Flux supports text-to-image, image-to-image, reconstruction, contextual reasoning, and high-speed creative workflows.
Nano Banana Image Models
Nano Banana is a fast, lightweight image generation model for playful, vibrant visuals. Optimized for speed and accessibility, it creates high-quality images with smooth shapes, bold colors, and clear compositions—perfect for mascots, stickers, icons, social posts, and fun branding.
Image and Video Tools
Open, advanced large-scale image generative models that power high-fidelity creation and editing with modular APIs, reproducible training, built-in safety guardrails, and elastic, production-grade inference at scale.
Ltx-2 Video Models
LTX-2 is a complete AI creative engine. Built for real production workflows, it delivers synchronized audio and video generation, 4K video at 48 fps, multiple performance modes, and radical efficiency, all with the openness and accessibility of running on consumer-grade GPUs.
Qwen Image Models
Qwen-Image is Alibaba’s open image generation model family. Built on advanced diffusion and Mixture-of-Experts design, it delivers cinematic quality, controllable styles, and efficient scaling, empowering developers and enterprises to create high-fidelity media with ease.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Hailuo Video Models
MiniMax Hailuo video models deliver text-to-video and image-to-video at native 1080p (Pro) and 768p (Standard), with strong instruction following and realistic, physics-aware motion.
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.
Z.ai LLM Models
The Z.ai LLM family pairs strong language understanding and reasoning with efficient inference to keep costs low, offering flexible deployment and tooling that make it easy to customize and scale advanced AI across real-world products.
Seedance 1.5 Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Its AI analyzes motion, setting, and timing to generate matching ambient sounds, then adds creative depth through spatial audio and atmosphere, making each video feel natural, immersive, and story-driven.
Moonshot LLM Models
The Moonshot LLM family delivers cutting-edge performance on real-world tasks, combining strong reasoning with ultra-long context to power complex assistants, coding, and analytical workflows, making advanced AI easier to deploy in production products and services.
Wan2.6 Video Models
Wan 2.6 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. Wan 2.6 will let you create videos of up to 15 seconds, ensuring narrative flow and visual integrity. It is perfect for creating YouTube Shorts, Instagram Reels, Facebook clips, and TikTok videos.
Flux.2 Image Models
The Flux.2 Series is a comprehensive family of AI image generation models. Across the lineup, Flux supports text-to-image, image-to-image, reconstruction, contextual reasoning, and high-speed creative workflows.
Nano Banana Image Models
Nano Banana is a fast, lightweight image generation model for playful, vibrant visuals. Optimized for speed and accessibility, it creates high-quality images with smooth shapes, bold colors, and clear compositions—perfect for mascots, stickers, icons, social posts, and fun branding.
Image and Video Tools
Open, advanced large-scale image generative models that power high-fidelity creation and editing with modular APIs, reproducible training, built-in safety guardrails, and elastic, production-grade inference at scale.
Ltx-2 Video Models
LTX-2 is a complete AI creative engine. Built for real production workflows, it delivers synchronized audio and video generation, 4K video at 48 fps, multiple performance modes, and radical efficiency, all with the openness and accessibility of running on consumer-grade GPUs.
Qwen Image Models
Qwen-Image is Alibaba’s open image generation model family. Built on advanced diffusion and Mixture-of-Experts design, it delivers cinematic quality, controllable styles, and efficient scaling, empowering developers and enterprises to create high-fidelity media with ease.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Hailuo Video Models
MiniMax Hailuo video models deliver text-to-video and image-to-video at native 1080p (Pro) and 768p (Standard), with strong instruction following and realistic, physics-aware motion.
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.

Uniquement chez Atlas Cloud.

