The World's Leading LLMs.
Ready for Any Conversation.
Power reasoning, coding, and natural language with enterprise-grade large language models.
Explore Our Expansive LLM Models
The latest Qwen reasoning model.
Qwen3 VL 30B A3B Thinking
The latest Qwen reasoning model.
Qwen3 VL 8B Instruct
The latest Qwen reasoning model.
Qwen3 VL 30B A3B Instruct
MiniMax-M2.7 is a lightweight, state-of-the-art large language model optimized for coding, agentic workflows, and modern application development. With only 10 billion activated parameters, it delivers a major jump in real-world capability while maintaining exceptional latency, scalability, and cost efficiency.
MiniMax M2.7
Qwen3.5 represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3.5 122B A10B
Qwen3.5 represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3.5 35B A3B
Qwen3.5 represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3.5 27B
Qwen3 Coder represents a significant leap forward, integrating breakthroughs in multimodal learning, architectural efficiency, reinforcement learning scale, and global accessibility to empower developers and enterprises with unprecedented capability and efficiency.
Qwen3 Coder Next
The Atlas Cloud Advantage:
Speed, Scale, and Savings
Our Model Library isn't just the largest. It's the most cost-effective, reliable, and production-ready. Proven performance, backed by data.
300+ Models, One Unified API
Multimodal, open-source, proprietary: all through one consistent endpoint.
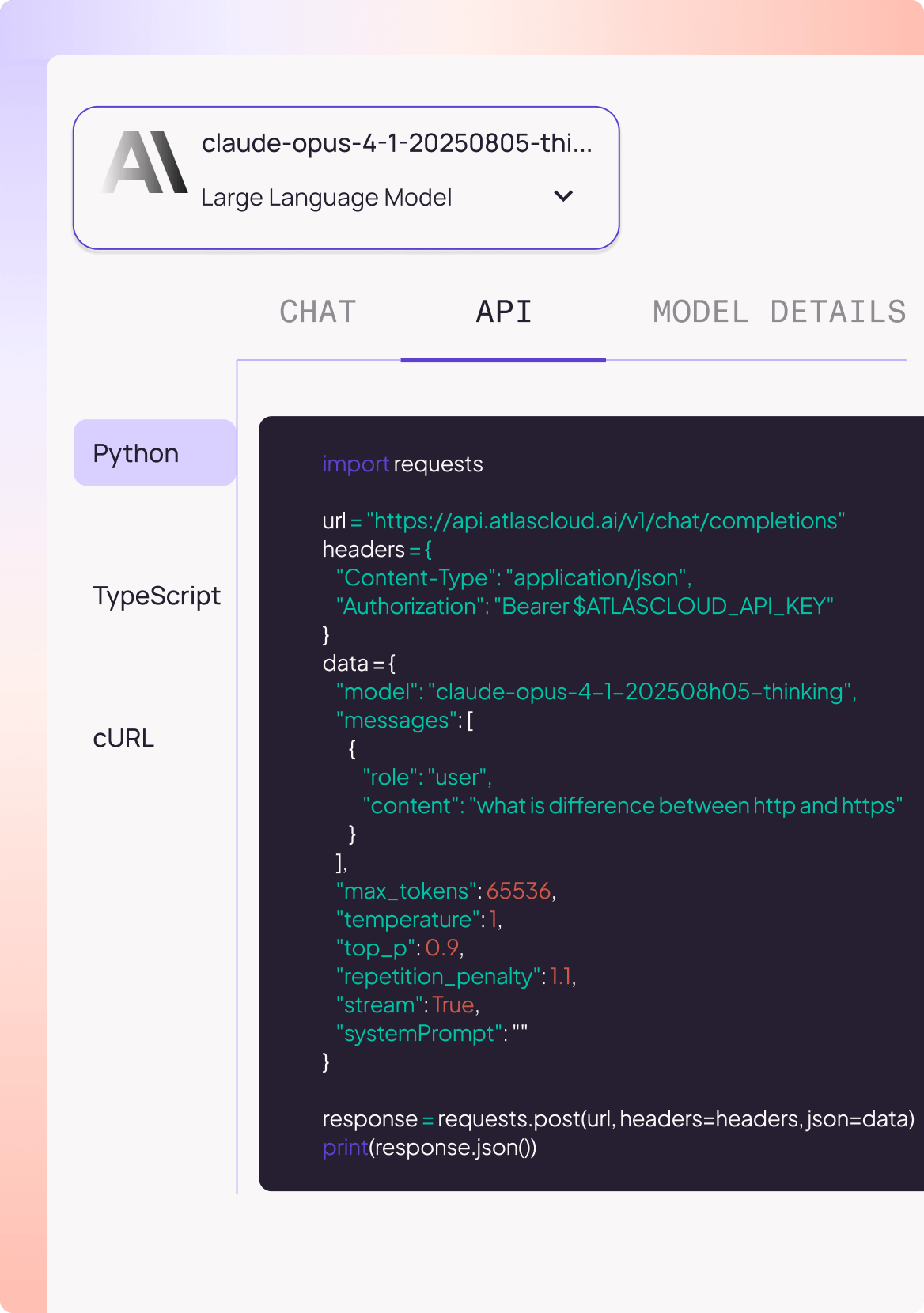
Serverless API Access
Start instantly with Python, TypeScript, or cURL, with no infra setup needed.
Proven Performance at Scale
10M+ API calls/month, 70+ TPS stability, deployed across 12 global regions.
Transparent & Flexible Pricing
Pay-as-you-go. Enterprise discounts up to 50%.